人類社會使用的文字種類數以千計,光是在我們的日常生活中,就會看到漢字、數字、歐文以及標點符號等字符。
但想讓只看得懂 0 與 1 的電腦儲存這些「字」,必須要先把這些「字」透過某種方式編碼(encoding)成二進位,等到要使用的時候再解碼(decoding)回原本的文本。
這個過程被稱作「字元編碼(character encoding)」,就像是一本雙語字典一樣,負責在人類語言以及電腦語言之間翻譯。在編碼過程時,先在字典上找尋與文本與對應的代碼;而解碼過程則與之相反,會回頭查詢與代碼相對應的文本。
假設在我們編寫的雙語字典——即「字元集(character set)」裡,「晚」這個字被放在第 50 個位置,而「安」這個字被放在第 51 個位置。在編碼階段,會把「晚安」轉成在二進位裡代表 50 的「110010」以及代表 51 的「110011」;而解碼時,只要反查「110010」與「110010」,就能找到對應的「晚」和「安」。

EBCDIC 與 ASCII 的嘗試
在電腦剛誕生的時候,大多只被用來處理複雜的計算任務,資訊交換的必要性極低,所以字元編碼一事還沒有被特別重視。
不過,在大型商業電腦與通用作業系統的出現後,電腦不再只是一台計算機,隨著各種應用程式落地發展,我們開始需要和陌生人、隔壁公司、甚至是他國交換資訊——但大家的字典都不一樣呀,要怎麼讓雙方都能無歧意的交換訊息?
此時,人們才總算意識到,我們需要一本共用的字典,也就是一套泛用的字元集標準。
IBM 的 EBCDIC 方案
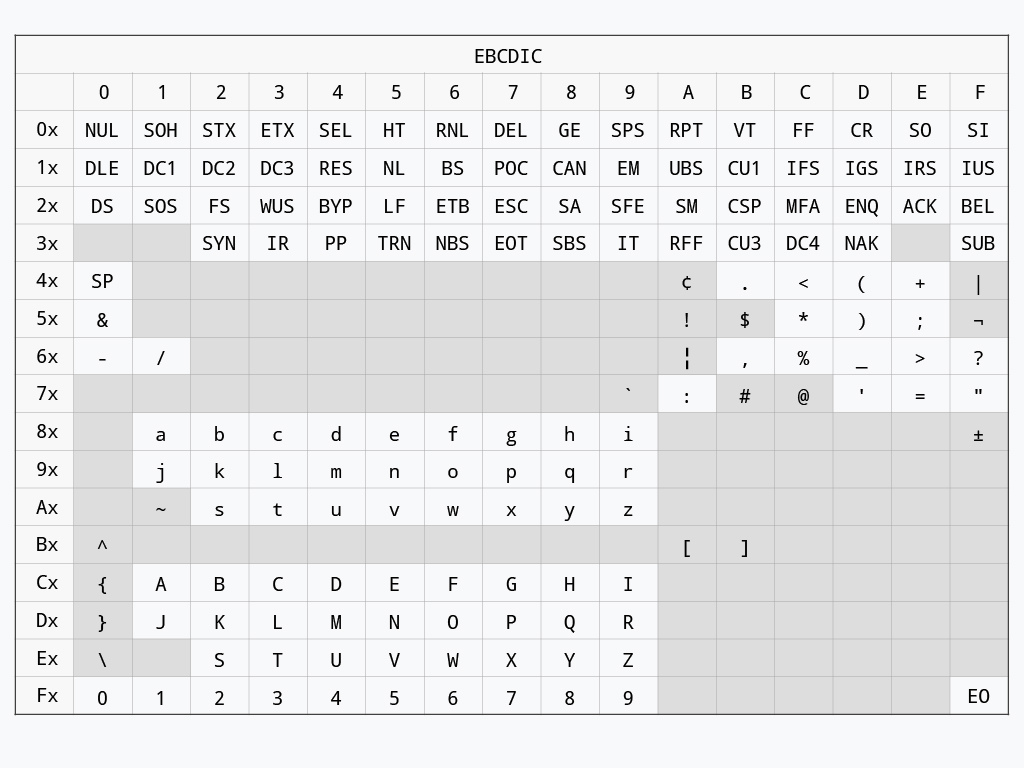
1964 年,作為當時大型商業電腦的領導者,IBM 公司推出了 EBCDIC(Extended Binary Coded Decimal Interchange Code,擴展二進位編碼的十進位交換碼)解決方案,嘗試將一些常用的符號與拉丁字母進行編碼。
如此一來,不同的電腦便能透過這本字典進行資料的交換與溝通。雖然 EBCDIC 開創了字元編碼的先河,但其設計時並沒有把英文字母放在連續的相鄰格子,這給程式處理帶來一定程度的麻煩。
ANSI(美國國家標準學會)的提案
四年後的 1968 年,ANSI(American National Standard Institute,美國國家標準學會)在檢討 EBCDIC 的優點與缺點後,發布了影響後世極深的 ASCII(American Standard Code for Information Interchange,美國訊息交換標準碼)編碼方案。
和前輩的 EBCDIC 最大的不同就在於,ASCII 將英文大小寫放在連續位置上,極大方便了程式的處理。

在 ASCII 的設計裡,七個位元(bit)來表示一個字,每個位元都可以是 0 或 1,因此共有 2^7=128 種組合,足以表示 128 個不同的字符——這個數量用來紀錄英文字母已經相當綽綽有餘。
另一方面,為了確保資料在傳送時的可靠性,廠商通常會額外在原有編碼之上添加一個位元,用作校驗使用。這個最高的位元通常被預留為 0,而每個字就是以這七個位元加上最高位的校驗位元,共八個位元來表示。
舉例來說,大寫的 A 在 ASCII 裡面被放在第 65 號位置(更前面還有符號跟看不見的控制字元),以位元來表示的話就是 0100 0001、小寫 a 則在第 97 個位置,以位元來表示的話就是 0110 0001。

擴充 ASCII
很快地,ASCII 在美國與英國獲得了成功,成為了那個年代裡最通用的編碼標準。但對於其他擁有變音字母的歐洲語言來說,例如法文 café 裡的 é,又該怎麼處理?原本規劃的 128 個格子已經塞滿了呀。
於是,有廠商把腦筋動到了最高位的位元上——反正目前這一位都是 0,只要把它改成 1,就可以再額外「擴充」出 128 個格子,用來放這些變音字母。像是 IBM 就曾替擴充拉丁文字、希臘文字、西里爾文字等設計擴充的 ASCII 方案。
簡而言之,由於使用八個位元來表示一個字符,只要該書寫系統所需的文字數量不多於 2^8=256 個,便能透過 ASCII 與擴充方案進行編碼交換。

但這種權宜之計依舊會遇到交換問題——如果我跟你的擴充方案不一樣,對應的字符就會是不同,「亂碼」就出現了。此外,當 1980 年代電腦登陸東亞市場,面對動輒數千,甚至數萬的漢字又要怎麼處理?
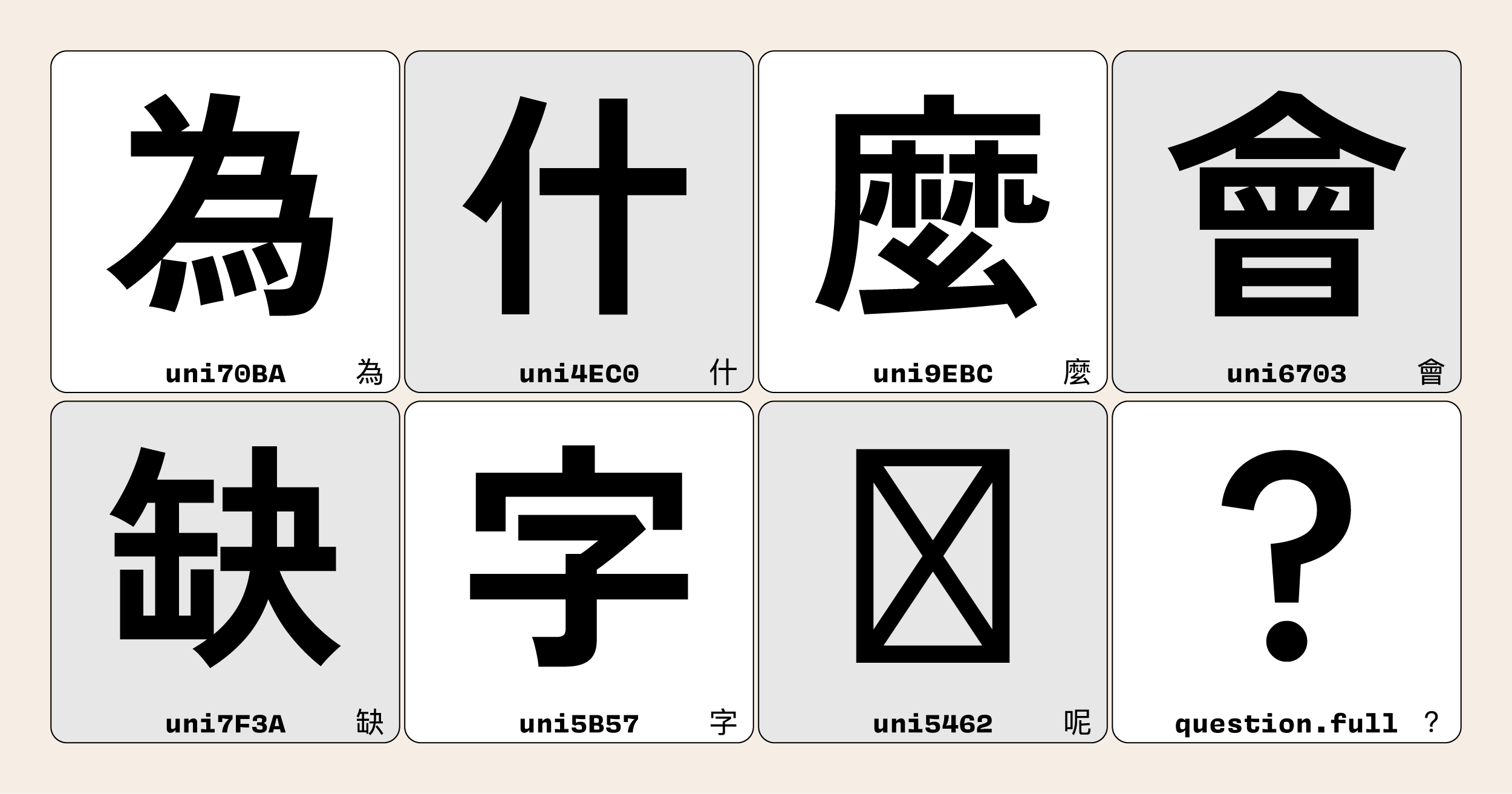
於是,東亞各國的電腦廠家便自行在原本通用的 ASCII 標準上進行額外的擴充,誕生出不同的地域標準,例如日本工業標準 Shift JIS、中國國家標準 GB2312、台灣業界標準 Big5 等等(註) 這些標準影響字型業界深遠,至今仍是許多廠商與設計師製作字型時,參考收錄的字符依據。這些編碼標準對於我們選字用字的影響請見〈下載字型前先看|為什麼會缺字〉。。
在 ASCII 嘗試統一編碼之後,我們很難過地又重回字元編碼的戰國時代,各個「標準」的高牆再度如雨後春筍般的築起,這對於資訊的推廣來說相當不利。
我們需要一個足以大一統的字符編碼標準,一本足以囊括全世界文字的字典。
Unicode 的統一
在混亂的背景下,1987 年,任職於 Xerox 的 Joe Becker、Lee Collins 和任職於 Apple 的 Mark Davis 萌生了統一字元編碼的想法並開始傳教。到了 1991 年,當時電腦界的大公司們聯手成立了 Unicode 聯盟(Unicode Consortium),希望能解決編碼標準不統一的問題。
在一開始,Unicode 聯盟將 ASCII 失敗的原因歸咎為擴充性不足——藉由八個位元來表示一個字,使其至多僅能放入 256 個字,這個數量實在太少了,不如改用 16 個位元來表示一個字,這樣就有 2^16 = 65,536 個格子可以用了,比 ASCII 多了 256 倍!用來收錄文字應該已經很夠了——嗎?
在 Unicode 1.0 釋出時,僅收錄了 24 種書寫文字、共 7,129 個字符。由於當時漢字的整理還沒結束,所以這個版本裡並沒有收錄漢字。
不過很快地,面對東亞各國不斷提交的新的漢字來源,以及眾多學術單位有將歷史文本電子化的需求,希望連已經消亡的古代文字都收錄進標準。面對大家爭先恐後提交的行為,Unicode 聯盟發現他們輕忽了標準所需的數量。
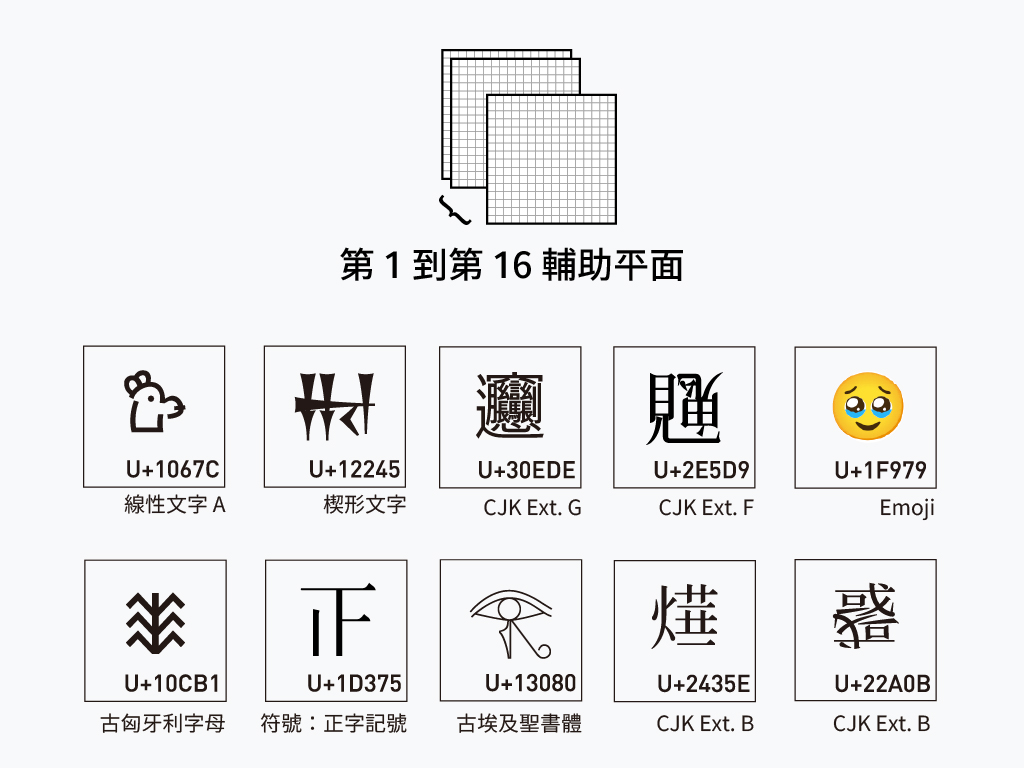
於是,在不改動原本規劃的 65,536 格子——後來這一區被稱作基本多語言平面(Basic Multilingual Plane, BMP)——之外,Unicode 聯盟額外規劃了第 1 到第 16 輔助平面(Supplementary Planes),每個平面都可以放入 65,536 個字符。(註) 不過在輔助平面中,每個平面的最後兩格保留作為系統辨識用,因此實際上每個平面僅可置入至多 65,534 個字符。
在這總共 17 個平面(plane)裡,至多可以容納 1,114,112 個字符,藉此來收錄那些或許你曾聽過的、也或許沒聽過,目前人類正在使用的,或是曾經在歷史上被使用過的文字。
,共-65536-個。第-1-到-17-平面為輔助平面(Supplementary-Plane),共-1048576-個。.jpg)
在經過 30 餘年的搜羅後,在 2023 年 9 月公告(也就是最近!)的最新版 Unicode 15.1 中,已經收錄了多達 161 種書寫文字,其中包含 94 種當代文字,以及 67 種歷史曾使用的文字,共 149,813 個字符。
當然,要把這麼多字都造出來堪稱天方夜譚,即便是 Adobe 和 Google 聯手開發的思源系列,也只滿足 BMP 與部分第二平面的字集。
而對於日常生活中的排版而言,7000 餘字已經(還是很多啦)相當足夠了。如果想要自己製作字型, justfont 的「jf 7000 當務字集」便是一個相對可行的造字目標。

Unicode 的表示方法
Unicode 習慣透過十六進位的方式表示字符的碼位(code point),並帶有「U+」的前綴。
在 BMP 上的字符碼位範圍為四位數的 U+0000 到 U+FFFF。而為了向下兼容 ASCII,前 128 個碼位,也就是英文字母與常見符號的區域,與 ASCII 的編碼相同,這讓使用 ASCII 紀錄的資料很容易的可以過渡到 Unicode 規格。
基本上,我們日常生活中會看到的文字,像是拉丁文字、阿拉伯數字、符號、常見漢字、日文假名、韓文、希臘字母、西里爾字母都是放在這一區。

而輔助平面則對應五位數編號的 U+10000 到 U+10FFFF。其中第一輔助平面放置了一些已經消亡的古代字母(像是楔形文字、埃及聖書體、線性文字),比較特別的是 Emoji 也被放在這一個平面上。
第 2 與第 3 輔助平面基本上都是一些極為罕見的漢字,提交源頭基本上都是姓名罕用字、地名罕用字、宗教用字(例如道教經書、神道教經書)、甲骨文隸定字或是古典裡的訛字。
第 4 到第 13 輔助平面目前都是空的(好消息是至少還有這麼多的空間可以放),第 14 輔助平面則是用來放置控制字元。
用私人使用區(PUA)的補足缺漏
雖然 Unicode 已經盡可能地羅列全天下的文字,但仍有相當多的文字因為尚待整理、還沒有共識而未被正式收錄。
例如瑪雅文字(Maya Script)與甲骨文,就因為寫法多變、標準化困難而仍處於草案階段。舉例來説,在之前甲骨文的草案中,就把「中」字的 19 個造型分開編碼,雖然彼此都有些微的差異,但對於是否應該要統一成同一形狀,還未有定論。
.jpg)
另外就是,Unicode 已經明定不會收錄人造或虛構的文字(註) 在 The Unicode Standard Version 15.0 中註明如下:Note, however, that the Unicode Standard does not encode idiosyncratic, personal, novel, or private-use characters, nor does it encode logos or graphics.(p.3),例如《魔戒(The Lord of the Rings)》裡的談格瓦(Tengwar)字母、《星艦迷航記(Star Trek)》的克林貢(Klingon)字母、流傳於文藝復興時期歐洲的底比斯女巫字母(Theban)就不在收錄範圍內。
,以及人造、虛構的文字(如克林貢文等),-scaled.jpg)
但這些沒有被收錄進 Unicode 的「文字」,在學術界或是同好圈子裡,仍然會有需要「交換」的時機呀,此時又該遵從哪套標準?
為了避免因為沒有被列入標準就無法被交換的尷尬情況發生,Unicode 將基本多語言平面的後半部(U+E000 到 U+F8FF,共 6,400 個碼位)以及第 15、16 平面(分別為 U+F0000 到 U+FFFFD,U+100000 到 U+10FFFD,各 65,534 個碼位)定義為私人使用區(Private Use Area,PUA)。
舉例來說,愛沙尼亞語言研究院(Eesti Keele Instituut,EKI)便曾經使用 PUA 放置那些還沒有被納入標準的衍生拉丁字符,例如 U+E00A 的「M WITH CEDILLA」;台灣的萌典也曾將 U+FF545 定義為客語用字「」(⿰皮卜,該字後來被正式收錄到 Unicode Ext-H,碼位為 U+31C7F)。
提供國家、私人12.-企業、組織、同好會、小圈圈等使用,概念類似約定俗成.jpg)
在 PUA 裡,每個編碼的樣子和意義都可以任由國家、私人企業、組織、同好會,甚至是自己去定義。一旦有其他人願意接受同樣的規則,私人使用區的碼位便有了意義,訊息的交換也有了可能。
尾聲
從最初 EBCDIC 和 ASCII 的發想與創立,到 Unicode 的統合與整理,字元編碼的進程可以說是當代網際網路世界得以交流的基礎,不僅促進了跨文化的互動,讓世界得以更緊密的連接在一起、溝通無礙;同時也妥善紀錄了人類社會的文化與歷史,讓過去的古籍經典得以數位的形式恆常保存。