
觀察日常生活中的物件,有沒有幾款字型頻繁出現在特定場合,讓你覺得很熟悉、但你始終不知道他的名字跟特點呢?
拿出你的身分證和護照,看看身分證背面右下角的綠色流水號字型,和護照資訊頁下排號碼的字型,是不是完全一樣呢?支票也是,不論是哪間銀行所發行的,下方都一樣有一排長相奇特的數字。其實,這幾款特殊字型,除了給人看,還有相當特別的用途──讓機器看。
讓機器學會讀字:光學字元辨識 OCR
讓機器看的字型?這件事得先從「光學字元辨識(Optical Character Recognition,OCR)」開始談起。

約 100 年前,英國伯明罕大學的物理學家 Edmund Fournier d’Albe 發表了一台能唸書給盲人聽的閱讀機器──「Optophone」。
利用「硒」元素面對光照強度的電阻變化特性,Optophone 可以感測光照到墨跡與空白處後的反射光,並依反射光的強度差異發出對應聲音。由於我們非理工專業,不便多談更細節的原理,但這就大致是 Optophone 能「讀」字的關鍵原理。(如果對 Optophone 感興趣,這篇文章供你參考。)可惜,當時的技術才剛起步,讀取速度慢又所費不貲,閱讀機器並沒有成功廣泛幫助視障者。
不過,Optophone 中,用來辨識印刷字的 OCR 技術沒有被大家放棄,大家對 OCR 技術的期望,從原先幫助視障者讀書,逐漸轉移到商業應用。
隨著技術發展,1951年,美國發明家 David H. Shepard 發明了第一台商用 OCR 機器;1954年,美國雜誌《讀者文摘》率先應用了 OCR 閱讀器,將打字機繕打成的紙本銷售報告,轉換輸入進當時用來儲存數位訊息的打孔卡(利用在不同位置打洞/不打洞來儲存數位訊息的紙卡)。
有了 OCR 閱讀器的加入後,企業得以自動化歸檔,不需仰賴人工辨識、騰打文字,成功提升歸檔效率。而後,郵政公司也利用此技術快速分類郵件,OCR 在人們日常生活的重要性越來越高。歸功於軟硬體的進步,現在,你只要有智慧型手機,就能使用到 OCR 技術,常見的用途包括:照相翻譯、紙本文件轉文字等,都幫我們節省了許多謄打的時間。
做一款讓機器更好看懂的字:OCR-A
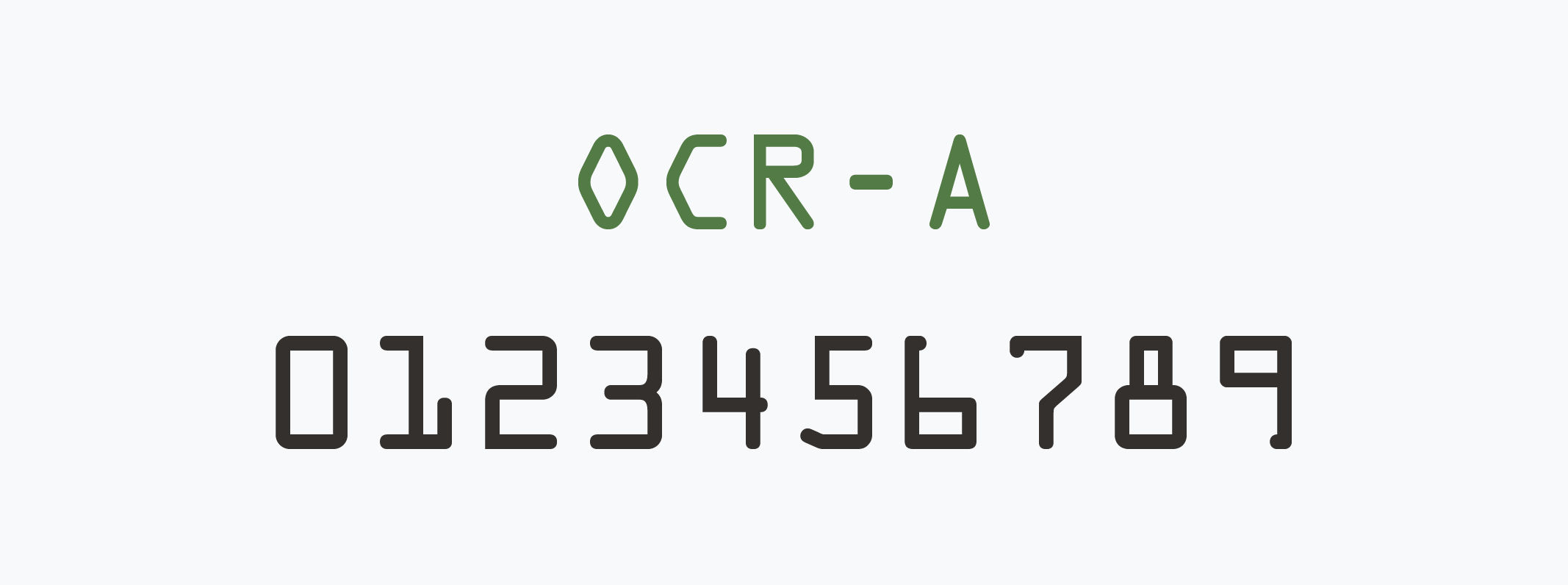
在那個 OCR 技術尚未成熟的 1966 年,為了讓 OCR 的辨識率更高更穩定,美國國家標準協會委託 American Type Founders ,製作了新款字型「OCR-A」。OCR-A 的筆畫寬度一致偏粗且字形簡單,加上等寬設定,讓機器可以輕易讀取與辨識、同時人類也有一定程度可辨識清楚。
還是希望可以好看一點:OCR-B
在 OCR-A 推出了兩年後,符合歐洲電腦製造商協會(European Computer Manufacturer’s Association,ECMA)制定通用標準的「OCR-B」也誕生了。這款由字型公司蒙納(Monotype)委託字型設計師 Adrian Frutiger 製作的 OCR-B,對機器和人類來說都不難看懂,也因此廣泛出現在生活中。前述提到在護照、身分證背面的號碼,正是 OCR-B 這款字型。

雖然和 OCR-B 相比,OCR-A 真的不太好(讓人類)看 ,但刻意充滿轉折的字形反而帶來了科技、電玩感。電影駭客任務(The Matrix,1999)海報上,主演姓名和上映日期用的就是 OCR-A,是不是很有科幻感呢?
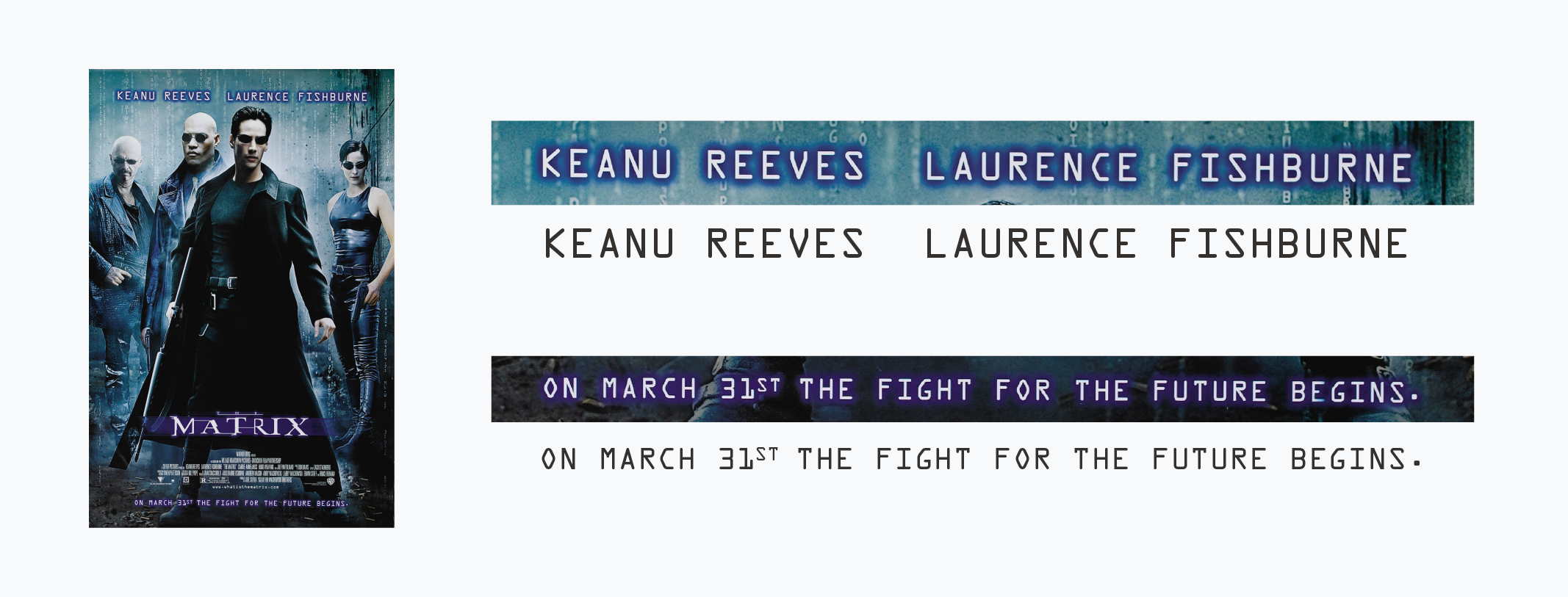
信用卡號的常見字型也與 OCR 有關:Farrington B
文章前部分提到,第一台商用 OCR 機器由發明家 David H. Shepard 所發明,其實除了機器外,他也開發了「Farrington B」這款字型。
為何要特別開發一款數字字型呢?當時,加油站是相對早開始使用 OCR 技術的場域,為了避免油污附著影響辨識,Shepard 開發了這款字形簡單、開放的數字字型。儘管到了科技發達的現在,信用卡已經沒有必要再使用這款字型,但它仍成為一個象徵,常出現在卡號有凸字設計的信用卡上。
如果機器用感應來讀字:磁墨字元辨識(MICR)與 E-13B
如果機器讀字不用「看」的,那還可以怎麼讀?
有用過支票的朋友也許會注意到,支票下方的那一排數字,長得有點古怪。數字筆畫粗細不均,整體看來也不太平衡,但大致還是認得出每個數字。

與 OCR 技術不同,支票上的編碼主要採用磁墨字元辨識技術(Magnetic Ink Character Recognition,MICR)。在印刷時使用可被磁化的油墨,而後就能透過 MICR 的讀取頭磁化墨跡、進一步感應辨識字元。
基於這樣的辨識原理,要讓 MICR 辨識的成功率提高,就得讓數字間的字形差異更大、有更多容納印刷油墨的空間。這就是為何專門用於 MICR 的字型「E-13B」(並不是星際大戰的某個機器人),要設計成這副模樣。
電腦能讀字成為日常,下一步可以去哪?
OCR 技術發展至今,不再像以往只能辨識特定字型。現在,無論是 LINE 或手機系統內建的 OCR 功能,都能辨識所有字體的字元,讓大家可以隨手用相機掃描文件的文字內容、直接拍照翻譯省略輸入步驟。雖然偶爾還是會因為種種原因(如:環境光線、畫面傾斜等等)辨識錯誤,但已大幅提升數位化的效率。
那接下來呢?
隨著人工智慧技術不斷發展以及跨領域介入應用,我們可以猜測 OCR 技術也會進一步的提升、並且應用於更多領域(聰明的機器人還是要看懂人類寫的字吧)。或許不久的將來,我們就能利用 OCR 技術輕鬆地識別出文宣所使用的字型名稱、辨識人類的草寫字、復刻各種版面格式。
對我們這些字體宅來說,聽起來還不錯,對吧?



