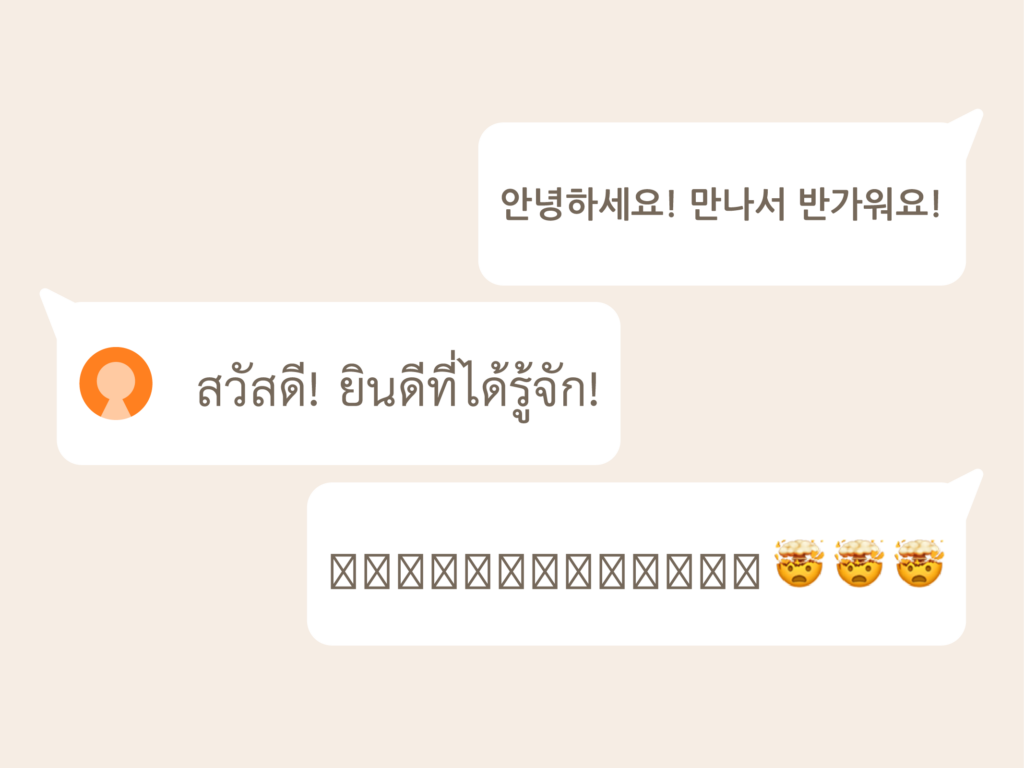
游錫方方土、亻厓講客、☐鮮價!
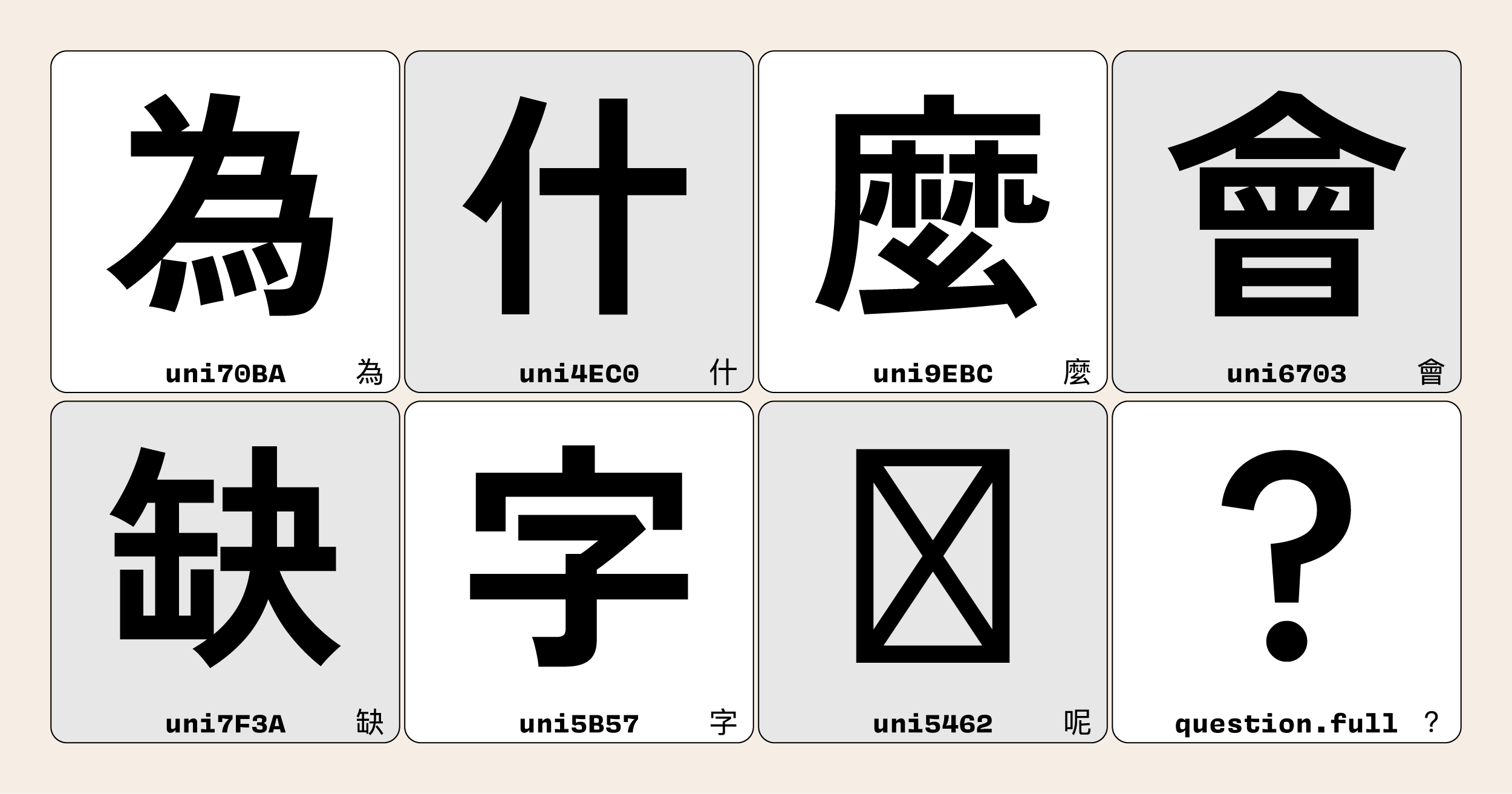
日常生活中,有時候會看見這種長得怪怪的文字編排,看得頭很痛。文字東漏一個西缺一塊,不只視覺上不好看,甚至導致閱讀理解困難。這些,是我們常說的「缺字」。要避免缺字,讓文字編排更好看,就必須先理解為什麼會缺字。
我知道!是輸入法害的!
嗯⋯⋯不完全正確。
造成缺字的原因有很多,最主要有兩種:1) 文字編碼問題;2) 字型支援程度。輸入法跟前者比較相關,但目前在大多數的情況很少遇到。後者是最普遍的缺字成因,也是本文要教你怎麼辨識和應對的重點。
而這兩個問題乍看之下不相關,其實背後的原因相同:字集。

什麼是字集
字集其實就像字典,告訴使用者有這些字的存在。人需要字典來認字,電腦也需要以字集為基礎,來查詢和辨識文字。試想一下,如果你寫了一段泰文給手邊只有韓文字典(也不會泰文)的人看,這個人是肯定讀不出來的。對電腦也一樣,如果你要求電腦顯示一段它查不到的字,那自然會出現缺字了。
既然都有字典了,那寫漢字讓用漢字字典的電腦讀,那怎麼還會缺字呢?
那是因為漢字實在是太・多・了!漢字因造字方法、寫法習慣、歷史關係等等,除了基本字,還有各式各樣的異體字。比如「山」在左或在上的「峰」、「日」在右或在下的「旭」等等。如果加上這些異體字,那中文字符量更是難以計數。教育部在 2017 年公佈的最新版《異體字字典》硬是衝破十萬,來到 106,330 字!
數字如此驚人,要一本字典收錄全部,不是什麼經濟實惠的選擇。生活中其實也不是真的需要用到這十數萬字,因此字典多半會有各自的標準與取捨。比如為了學童而生的《國語日報辭典》僅收錄 9,238 字,教育部整理的《常用國字標準字體表》加上《次常用國字標準字體表》則有 11,149 字。

當然,電腦查的不會是紙本字典,另有數位字集。與紙本字典相同,數位字集也需要衡量需求,取捨收錄的文字與字數。再加上異體字、地區差異等等,光是與漢字相關的字集,就有數十種可以參考。
連編纂字集都耗時費力了,要每一套字型都達到《異體字字典》那樣十數萬字的目標,實在是太強人所難。因此字型設計時,便是參考這些經過整理的字集,製作出相應的字符。如果你使用的字型參考的字集裡面沒有收錄你需要的字,那缺字就是必然了。
所以在買字之前,看清楚字型參考的字集,可以有效避免買到不符需求的字型。大部分的字型廠商會提供產品規格,註明支援字集,十分一目瞭然。再者,多數的字型銷售、下載管道(如 Adobe Fonts、Google Fonts、MyFonts 等)都會提供試打區,可以透過以下這段文字來推測這個字型的支援範圍:

常見的數位字集有哪些
繁體中文
堪稱業界標準的 Big5(大五碼或五大碼)
Big5 堪稱目前繁體中文字型業界的字集標準。1980 年代,民間企業因為急迫的使用需求,與資策會共同製作,有些倉促地推出。在當時因為沒有太多其他字集選擇,再加上幾家軟體大廠都採用,遂成為繁體中文市場默許的業界標準。
然而 Big5 編制時,主要參考的是教育部的常用與次常用標準字體表,因而缺乏許多異體字,也缺乏許多香港常用字和本土語言用字。除了參考標準侷限外,倉促編制、年代久遠,都讓 Big5 不是太好用。
雖然最新的 2003 年版本收錄 13,060 字,乍看字數不算少,但在當代仍顯得不合時宜,也因此多數字型廠商會自主增加字數。比如 justfont 的多數字型產品即是以 big5 為基準擴充,收錄達 14,000 以上。

不容易缺字但也過度龐大的全字庫(CNS11643)
同樣起源於 1980 年代,全字庫由行政院主導。雖然初期因為收錄字數不符需求而未能成為標準,但數十年來持續更新,目前收錄字符數量近 109,000 (包含符號等)。除了字符外,全字庫也提供明體、宋體、楷體三種字型檔。
雖然全字庫是個很難遇上缺字的字集,但十萬多字的規模太過龐大,除了少數支援戶政需求的字型外,很難有什麼字型能夠達到這個標準,一般消費者能買到的字型選項中也自然難有支援全字庫的選項了。

香港政府自主增補的香港增補字符集(HKSCS)
Big5 雖然在時勢之下成為業界標準,但因為收錄標準主要參考台灣教育部的《標準字體表》,未能收錄許多香港常用字。因此香港政府基於 Big5,自行增補香港常用字如街道用字、粵語用字等,做成《香港增補字符集》(Hong Kong Supplementary Character Set, HKSCS)。如果你有香港常用字需要,記得確認購買的字型是否支援。

日文
日本國家標準的 JIS(日本產業規格)
這是由日本產業標準調查會制定,是日本國家級標準。JIS 標準裡又分第一到第四水準:第一水準為日本生活現場最常用的漢字與人名;第二水準追加較少用的地名、人名等特殊用途的漢字;第三水準則是為專業目的編纂,包含更多特定領域用字和符號,如醫學等;第四水準又比第三水準更加專業、罕用。
部分獨立設計師製作的日文字型即是參考 JIS 規格。但一般免費日文字型僅支援 JIS 第一或第二水準,對繁體中文情境而言,太容易遇上缺字,不是非常好用,下載前請務必確認支援範圍。

絕大多數日文字型採用的 Adobe-Japan1
由印刷設計領域大廠 Adobe 推行的字集,也是現今日本字型業界的標準,電腦內建的多數日文字型都符合。Adobe-Japan1-0(簡稱 AJ0)在 1993 年推出,目前已更新至 Adobe-Japan1-7(AJ7),市場上流通的主要為 AJ3 到 AJ6(與 AJ7 只差了「令和」的組合字符)。AJ3 支援 JIS 第一與第二水準,對日本的用字情境而言,是很好用的基本字集了。而 AJ4 則是為商務印刷編制,新增許多人名用字與商業符號,可應用的場合比起 AJ3 更加專業。AJ5 與 AJ6 則新增支援了 JIS 第三、第四水準。
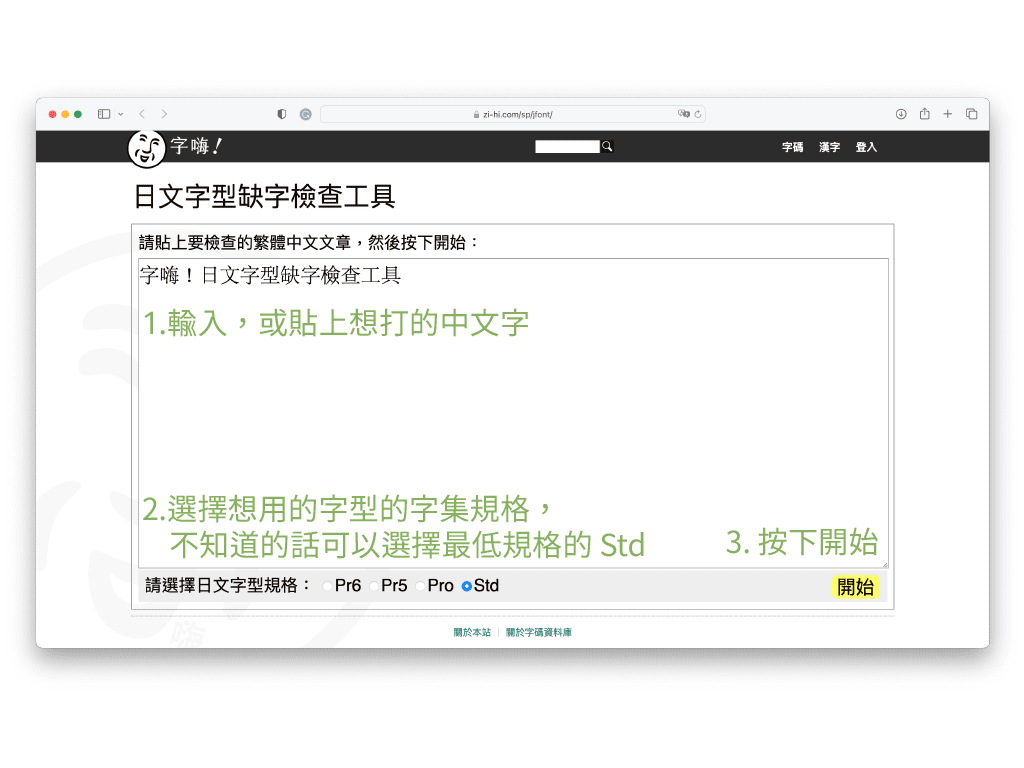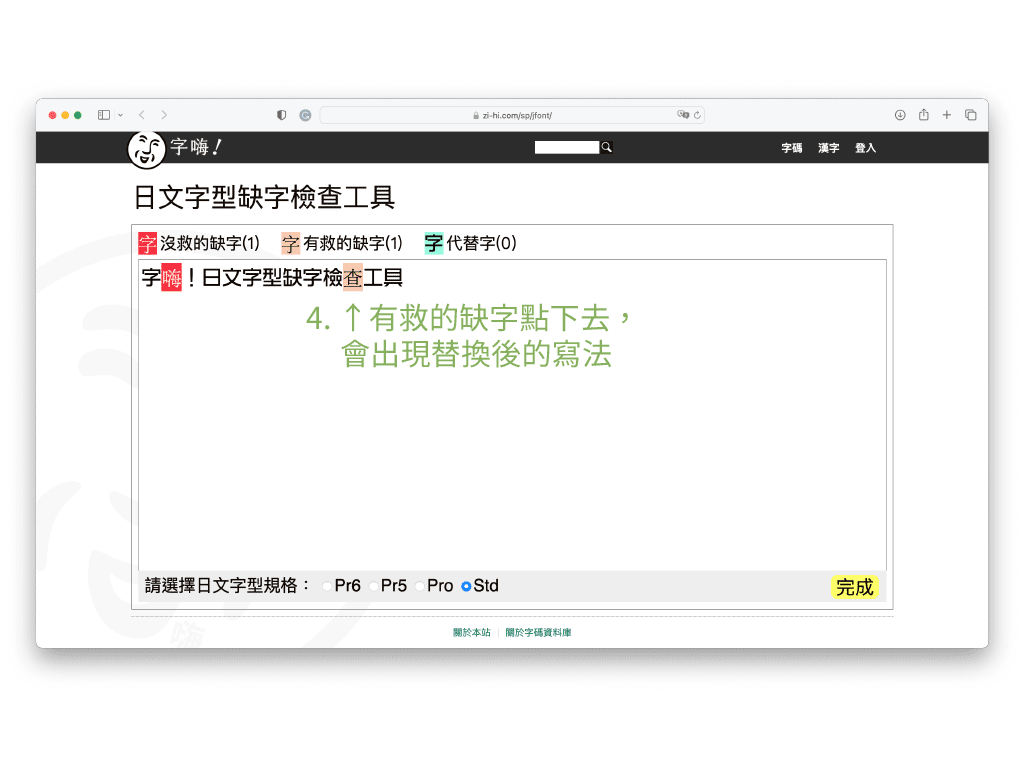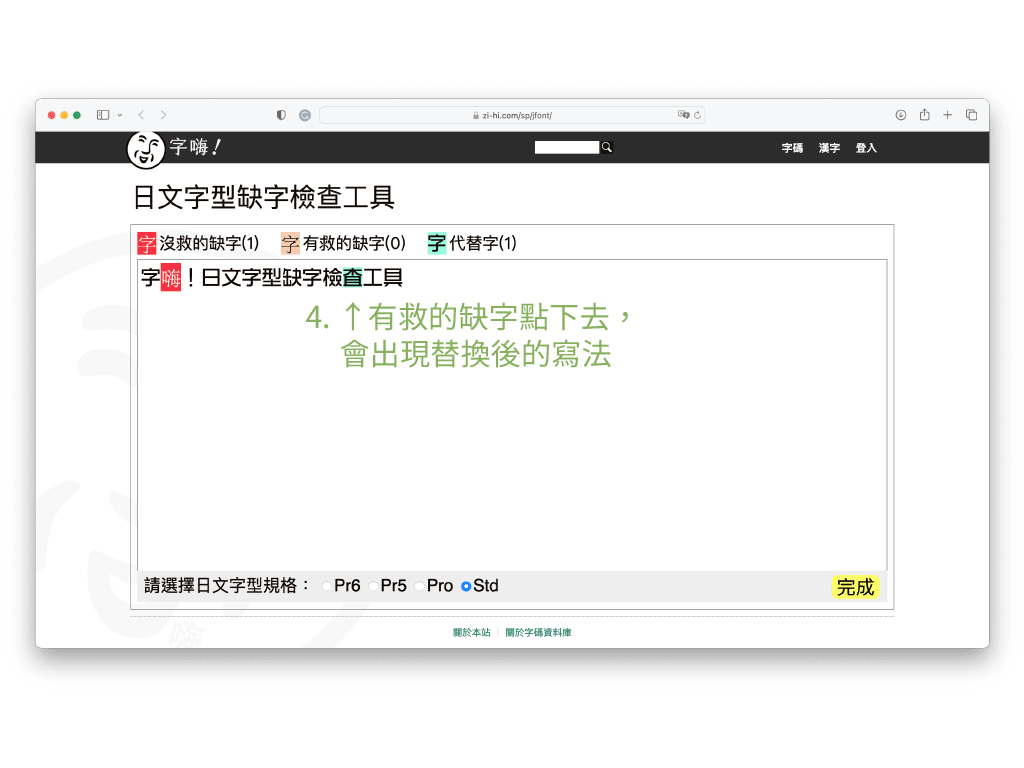
不過 AJ3 以下(含)沒有如「你」這類很常用的基本字,「哪」、「呢」、「嗎」等字在 AJ5(含)以上才收錄,因此繁體中文用字情境裡,還是有很大機會遇上缺字。這時候可以用字嗨社長 But 製作的日文字型缺字檢查工具,不僅可以查狀況,還可以看怎麼補救。
簡體中文
中國國家標準 GB
中國頒布的國家級標準簡體中文字集取「國標」二字的拼音字首,簡稱為 GB。最初頒布 GB2312,可以支援決大部分的使用情境。但隨著時代進展,用字習慣改變,再加上仍有許多罕用字、特殊用字、人名用字並未被收錄,因此中國再將字集擴充成為 GB18030。
雖然 GB 收錄了部分繁體字,但到底是簡體字為主的標準,在繁體使用情境裡的缺字情況可想而知。另外,雖然 GB 並未直接規範寫法,但通常支援 GB 的字型會同步參考中國在《通用規範漢字表》中規範的寫法,因此會出現與繁體習慣不同的筆畫,需要特別注意。

支援字集該怎麼看
說了這麼多,作為字型使用者,我們其實不一定需要知道字集到底收了多少字或哪些字。但在購買、下載字型之前,懂得判斷該字型所參考的字集標準,可以有效避免用了之後才發現不符需求的狀況。
判斷的方式有很多,最直觀的就是字型廠商的官方說明。大多的字型廠商會在產品敘述中註明該字型支援的字集,可做為參考。而繁體中文廠商若註明 Big5,則通常會額外增加部分常用字。
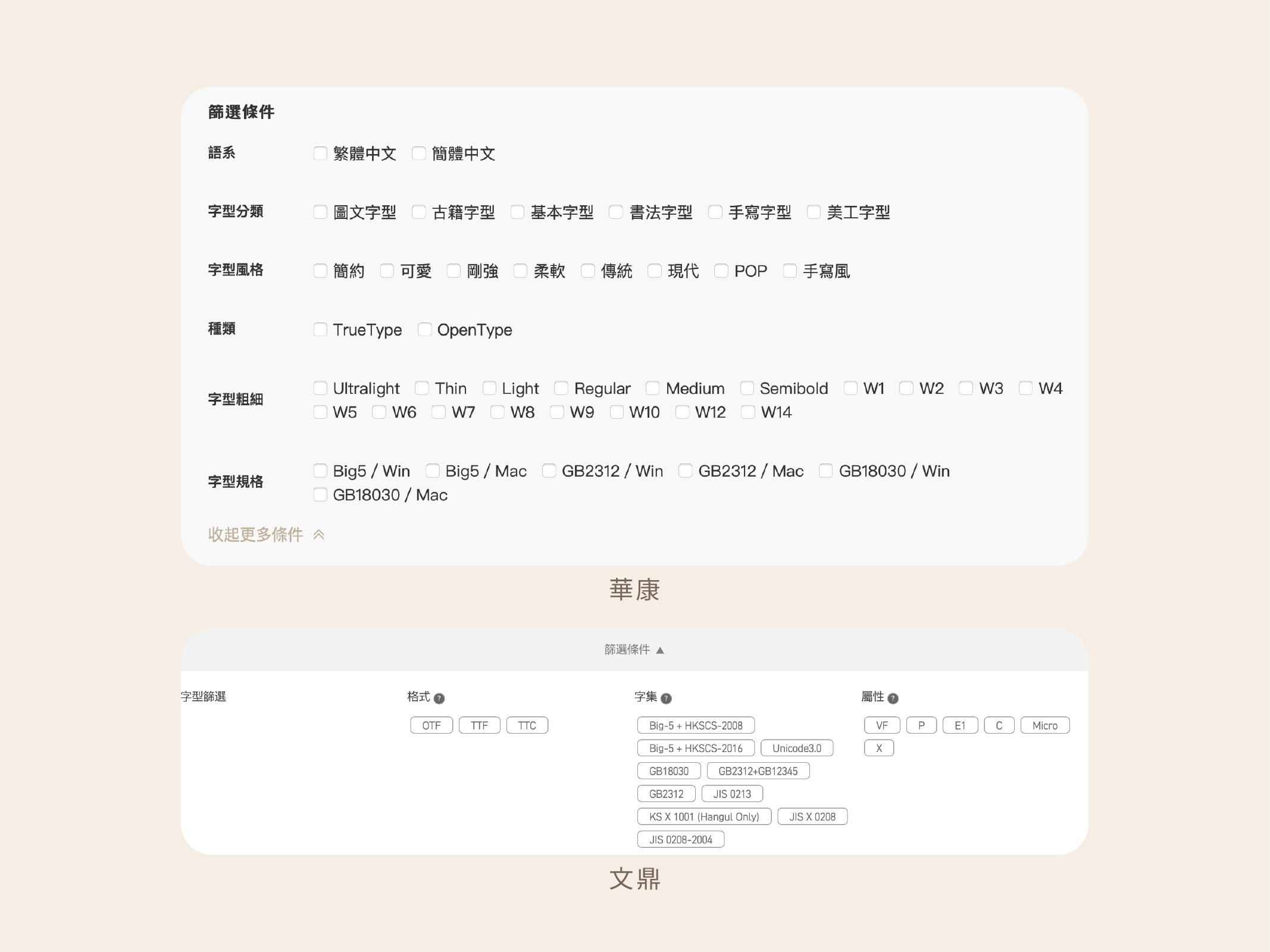
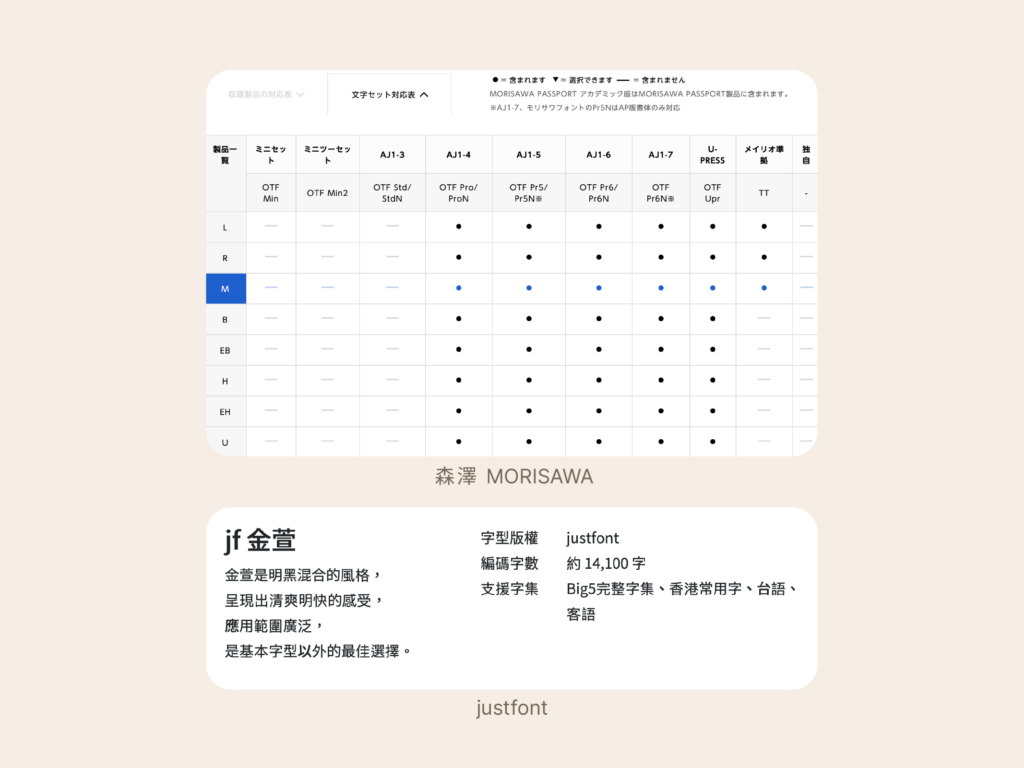
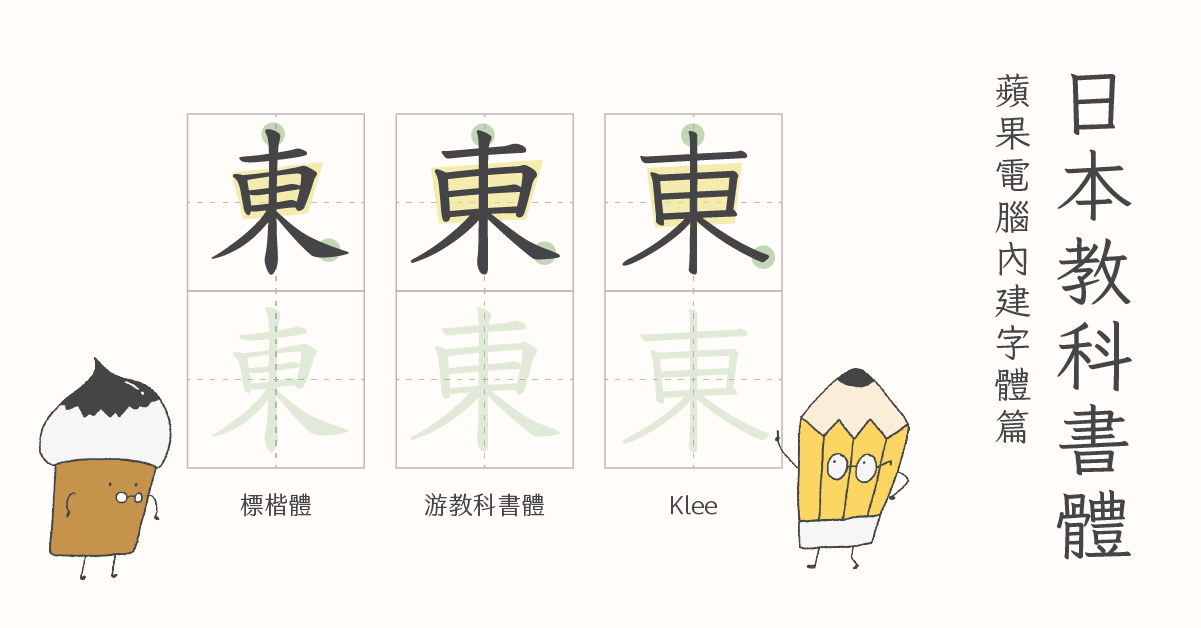
日本的字型大廠還會在產品名後加上後綴,表示字型支援的字級範圍。AJ3 的後綴為 Std、AJ4 為 Pro、AJ5 為 Pro5,以此類推。在電腦中已經有字型檔時(比如內建字型)尤其有幫助。

當然,也可以用本文開頭提供的測試句,在試打區快速判斷該字型的支援範圍。
獨立設計師的作品,或者部分不支援常見字集的產品,可能會改以支援字數表示。畢竟這些常見字集動輒上萬字,對於字型大廠而言也不總是有辦法負荷,何況獨立設計師。
在沒有列出字集規範的狀況下,若以一般使用不缺字為目標,則建議字數要到 7,000 以上才比較保險,也要注意是否有支援注音和英數字。
以上介紹了幾種常見的字集,以及如何測試字型支援的範圍。此外,也還有許多字集參考,比如「再會豆腐字」就整理出台灣本土語言的字符(包含羅馬字),希望盡可能跟缺字的豆腐說再見。
但終究因為漢字的特殊性,要一套字型完全不缺字幾乎是不可能的。作為消費者可以做的,就是好好了解自己的用字需求與字型支援的字集範圍,並且支付相應的費用,支持設計師們持續做出更多符合需求的字型了。